Document Filters Overview
dtSearch products
embed dtSearch’s proprietary document filters to support a broad range of data
types. What are
document filters? (PDF)
- For all supported data types, support covers parsing, indexing and searching
of retrieved full-text and metadata.
- The document filters can also convert non-web-ready content like Microsoft
Office document and email formats "on the fly" to HTML for
web-based display, etc., with highlighted
hits. See also dtSearch
Web and the dtSearch Engine
Supported Data Types
dtSearch’s proprietary
document filters support parsing, indexing, searching and display with highlighted
hits of text and metadata across a broad range of data
types.
- PDF: PDF through PDF 2.0; PDF
Portfolio
- Microsoft Office: Word, Excel, PowerPoint, Access, OneNote files, including
Office 365
- Other "office": OpenOffice; certain international office formats;
XBASE; CSV; SPL; multi-format image/sound/video metadata support; etc.
- Compression formats: RAR, ZIP, GZIP and TAR
- Emails: Exchange, Outlook, Thunderbird, etc. with multilevel nested
attachments
- Web data: HTML, XML/XSL, PDF, ASP.NET, CMS, PHP, WordPress, SharePoint, etc. See also: cloud storage
- Through APIs: NoSQL / SQL data including
BLOB data; other non-file data like network data streams; Azure and AWS data stores
- Full list of supported document
types.
Federated Searching and the dtSearch
Spider
dtSearch products provide federated search across any number
of directories, emails (with nested attachments), and databases. 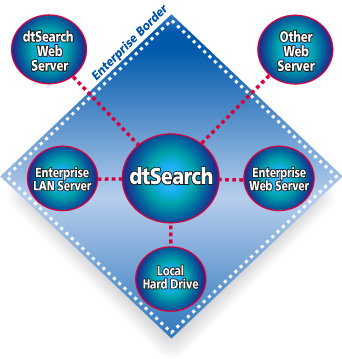 The dtSearch
Spider adds local and remote online content to a search. The Spider can index
sites to any level of depth, with support for public and secure online content,
including log-ins and forms-based authentication. dtSearch products provide
integrated relevancy ranking with highlighted
hits across both online and offline data. Note: for
developers, the Spider is presented as a .NET API. The dtSearch
Spider adds local and remote online content to a search. The Spider can index
sites to any level of depth, with support for public and secure online content,
including log-ins and forms-based authentication. dtSearch products provide
integrated relevancy ranking with highlighted
hits across both online and offline data. Note: for
developers, the Spider is presented as a .NET API.
Document Filter APIs
All developers APIs (C++,
Java and .NET through current versions) make available to developers dtSearch’s
text parsing, extraction, conversion and hit-highlighting capabilities.
- An “object extraction” API lets developers navigate through the structure of
each embedded object as a hierarchy, and optionally extract each object,
such as an image in an MS Word file embedded in an MS Access database,
compressed and attached to an email.
- General dtSearch Engine licenses include the document filters along with
dtSearch indexing and searching functionality.
- The document filters are also available for separate license for developers
requiring text parsing, extraction and conversion “only,” without search.
|
