⮞ View Other Features Map Topics
Indexing and Searching Features of Special Interest to Forensics Users
Before You Start, See:
- key dtSearch forensics and e-discovery search tips from InsideCounsel “Optimize Searching to Find Every Smoking Gun”
- automated indexing via the Windows task scheduler and other general information
- optimizing indexing of large volumes of data FAQ
dtSearch does not alter original files or other data, including hash values, in indexing, searching and display of documents.
dtSearch also does not send your documents, indexes, search request data and the like back to dtSearch Corp.
Federated Searching and the dtSearch Spider
dtSearch products provide federated search across any number of directories, emails (with nested attachments), and databases. No need to tell dtSearch what files, emails or other content you have; dtSearch will figure that out for itself. Indexing, searching and display of documents does not alter original files or other data, including Hash values. More Information
dtSearch’s own document filters support parsing, indexing, searching and display with highlighted hits of text and metadata across a broad range of online and offline data types.
- PDF: PDF through PDF 2.0; PDF Portfolio
- Microsoft Office: Word, Excel, PowerPoint, Access, OneNote files, including Office 365
- Other "office": OpenOffice; certain international office formats; XBASE; CSV; SPL; multi-format image/sound/video metadata support; etc.
- Compression formats: RAR, ZIP, GZIP and TAR
- Emails: Exchange, Outlook, Thunderbird, etc. with multilevel nested attachments
- Web data: HTML, XML/XSL, PDF, ASP.NET, CMS, PHP, WordPress, SharePoint, etc. See also: cloud storage
- Through APIs: NoSQL / SQL data including BLOB data; other non-file data like network data streams; Azure and AWS data stores
- Full list of supported document types
After a search, dtSearch products provide integrated relevancy ranking with highlighted hits across both online and offline data. For files that may not be readily accessible at search time, you can build the index with caching enabled.
The dtSearch Spider adds local and remote online content to a search. The Spider can index sites to any level of depth, with support for public and private or secure online content. For private or secure sites, the dtSearch Spider supports log-ins and forms-based authentication. For public sites, the dtSearch Spider is a “polite” spider and will not index and search a site with a flag that indicates it does not accept spiders or robots.
For convenient offline access, the dtSearch Spider also includes a caching option, to store the full spidered content along with the index. (Without caching, the Spider has to return to the relevant URL to display the full content with highlighted hits.) The caching option can also be used with other, non-spidered data as well.
The document filters also convert non-web-ready content like Microsoft Office document and email formats "on the fly" to HTML for posting on the web.
dtSearch does not use file extensions to determine a document's file type. For accuracy, dtSearch looks inside each document to determine the relevant file type. Accordingly, if any PDF files have .DOCX extensions and any MS Word documents have .PDF extensions, dtSearch will still parse them appropriately.
PDFs and OCR
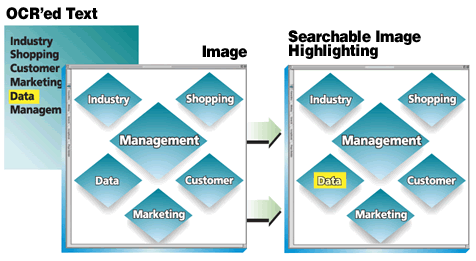
Searchable PDFs. dtSearch recommends using an OCR program like Adobe Acrobat to OCR scanned images into PDF “searchable image” format. If a PDF file is an “image only” PDF (i.e. a PDF where even though you can see text, you cannot cut and paste that text), use an OCR program like Adobe Acrobat to turn the “image only” PDF into a “searchable image” PDF.
The View Log function available after an index updates can report “image-only” PDF files in the index update log. This reporting will indicate if there are any PDF files that require OCR to enable full-text search. (Alternatively, after an index update, look in the index folder for a file named IndexLog_ImageOnlyPdf.txt. This will be a plain-text list of filenames of all files that look to dtSearch like image-only PDF files.) Note that metadata in “image only” PDFs files is indexed in any case.
The "searchable image" format works by storing the complete original image of a scanned document, along with the text obtained through OCR. The text is "hidden" in the sense that simply opening the PDF file displays only the scanned image, not the underlying OCR’ed text. Because the OCR’ed text is "hidden" in the file, however, dtSearch can index and search it.
PDF Portfolios. A PDF portfolio can contain any combination of PDF or other document types. dtSearch converts the whole PDF portfolio, with all embedded documents, to a single formatted text stream and indexes it as a single file. After a search, dtSearch can highlight hits by converting the PDF portfolio contents to HTML. (An alternative to the "single file" treatment for developers is to use the ExtractionOptions object in the API to break apart the PDF portfolio and extract its components.)
PDF Encryption. dtSearch products support indexing PDF files with 40-bit RC4, 128-bit RC4, 128-bit AES, and 256-bit AES encryption. Exception: if a PDF file has “Restrict editing and printing of the document” selected, and does not have “Enable copying ...” selected, then dtSearch products will not access that PDF file.
To access security and permission settings in a PDF file, open the file in Adobe Acrobat, click File from the top menu, then select Properties and then select the Security tab. If you select Password Security from the drop-down list, one of the options is “Restrict editing and printing of the document.” If that is selected, and “Enable copying ...” is not selected, then dtSearch products will not access that PDF file until those settings are changed. Adobe Acrobat requires entering the original password to change these settings.
To index encrypted PDFs that dtSearch does not support (i.e. PDFs with the “Enable copying ...” permission disabled or PDFs requiring a separate password), make a temporary, decrypted copy of the encrypted files, index the decrypted copy, and then replace the temporary decrypted copy with the encrypted versions. This one-time unencryption is sufficient for dtSearch operation. dtSearch does not need to unencrypt the PDF files to search and display them with highlighted hits once the original index is complete.
Developers: PDF encryption support is subject to export restrictions. Please see Section 12.4 of the dtSearch setup license agreement for more information.
PDF Association Article: "How you see PDFs versus how a search
engine sees PDFs."
Excerpt: "The way a search engine like dtSearch handles this issue is to look
at the binary file ... [A] binary format PDF can enable a search engine and its document filters to 'see' text that
might easily escape scrutiny in an associated application display." Full Article
PDF 2.0. More than 25 years after Adobe created the PDF file format in 1993, there is a major new version of PDF: PDF 2.0. Because this new PDF version changes the header information, dtSearch versions before 7.93 will not recognize the PDF 2.0 file format and will miss all content in these files. Therefore, it is essential to use dtSearch 7.93 or later before attempting to index and search PDF 2.0 files.
View Log of Encrypted Files
After an index update completes, click "View Log" to see a report that will include information on any encrypted or unreadable files that the indexer could not process. This report can be accessed at any time in the index folder in the file Index_LastUpdateErrors.html. The report indicates which files were (a) encrypted, (b) corrupt, (c) partially encrypted, and (d) partially corrupt. Partially encrypted or corrupt files are files that could be indexed in part but that included some encrypted or corrupt data, such as an email with an encrypted attachment. (See above topic for additional information on encrypted PDFs.)
Automatic Recognition of Dates
dtSearch can automatically recognize dates and search for date ranges even if the dates are expressed in different text formats. Date and date range searching can automatically extend across popular date formats enabling a search for date(10/20/25 to 1/5/25) to pick up not only 10/31/25 but also October 31 2025 and Oct 31 2025. dtSearch can also extract all dates from a collection of files. More information
Personally Identifiable Information (PII): Email Addresses, Credit Cards, Social Security Numbers
Email addresses. dtSearch can automatically recognize email addresses and extract all email addresses from a collection of files. More information
Credit card numbers. Credit card number recognition looks for any sequence of numbers that appears to satisfy the criteria for a valid credit card number issued by one of the major credit card issuers. dtSearch recognizes credit card numbers regardless of the pattern of spaces or punctuation. dtSearch further uses an internal credit card identifier code to tell if the digits together represent a valid credit card number. dtSearch can also extract all credit card numbers from a collection of files. More information
Social security numbers.
Social security numbers do not themselves include the same type
of identification code verification options as credit card
numbers. However, dtSearch can use numeric pattern searching to
locate social security numbers and other numeric patterns. More
information
Forensics Filtering Features
dtSearch offers a Unicode filtering feature for automatic recovery of text from corrupt forensically-recovered documents and large data blocks, such as those recovered through an "undelete" process, from unallocated computer space, or from partially recovered file fragments. The filtering algorithm can scan recovered data blocks using multiple Unicode and other text encoding detection methods. More information
- dtSearch Desktop/Network: Click Options > Preferences > Filtering Options, and check the "Filter text" option under "Binary files" to enable filtering of binary files.
- dtSearch developer API: Set Options.BinaryFiles = dtsoFilterBinaryUnicode.
Emails, Messages, Contacts, Appointments and the Like
dtSearch products offer several options for indexing and searching emails and other messages, contacts, appointments and the like. All methods support indexing, searching and display with highlighted hits of item content, metadata and attachments, including multilevel nested email attachments. Options for indexing Outlook and Exchange messages.
Fuzzy Searching
Fuzzy searching uses a proprietary algorithm to find search terms even if they are misspelled. dtSearch recommends fuzzy searching for searching emails, OCR’ed text, or any other text that may contain misspellings.
Search fuzziness adjusts from 0 to 10 so you can fine-tune fuzziness to the level of OCR or typographical errors in your files. A search for alphabet with a fuzziness of 1 would find alphaqet; with a fuzziness of 3, it would find both alphaqet and alpkaqet. Fuzziness is not built into the index, so you can vary fuzziness at the time of each search. More information on fuzzy and other search options
SHA-256 and MD5 Hash Support
Hash values are unique numerical codes that are sometimes used in forensics to identify files. Indexing, searching and display of documents does not alter original files or other data, including Hash values. Learn more about how dtSearch works
Starting in V. 7.86, dtSearch has an option to generate an MD5 hash for each document as it is indexed and append the field to the document text as searchable metadata. Starting in V. 7.87, dtSearch has an option to generate an SHA-256 hash for each document as it is indexed and append the field to the document text as searchable metadata.
As with other dtSearch indexing operations, this process will not alter the original files or their hash values. This option will, however, make indexing slower.
- dtSearch Desktop/Network: Click Options > Preferences > Indexing Options, and check "Generate and index MD5 hashes for documents" or "Generate and index SHA-256 hashes for documents"
- dtSearch developer API: Options.FieldFlags: dtsoFfGenerateMd5Hash or Options.FieldFlags: dtsoFfGenerateSha256Hash
International Language Support
dtSearch includes Unicode-compatible file parsing, to convert input data to Unicode. dtSearch supports hundreds of different international languages through Unicode.
The following dtSearch search options work automatically on text in any international language: phrase; Boolean; proximity and directed proximity; wildcard; macro; numeric range; fielded data / metadata search options; fuzzy searching (adjustable from 0 to 10 to account for typographical or OCR errors); and relevancy-ranked searching (including automatic term-weighted ranking, positional scoring options, general variable term weighting, variable term weighting in fields, and other API-based document classification and sorting options). More information
Chinese, Japanese and Korean Text With No Word Breaks
Some Chinese, Japanese, and Korean text does not include word breaks. Instead, the text appears as lines of characters with no spaces between the words. Because there are no spaces separating the words on each line, dtSearch sees each line of text as a single long word. To make this type of text searchable, enable automatic insertion of word breaks around Chinese, Japanese, and Korean characters, so each character will be treated as single word.
- dtSearch Desktop/Network: In Options > Preferences > Letters and Words, check the box to “Insert word breaks between Chinese, Japanese, and Korean characters in text.”
- dtSearch Developer API: set dtsoTfAutoBreakCJK in Options.TextFlags.
Note: this setting will only affect text identified as Unicode Chinese, Japanese or Korean text; it will not affect text identified as other Unicode character sets.
Language Group Identification
For documents in certain formats that do not include encoding information, such as single-byte text files, dtSearch provides a proprietary language recognition algorithm for detecting text in a large variety of languages (Western European, other European, Middle-Eastern, etc.). This algorithm is enabled by default.
Hidden Content
A search in dtSearch will always include white-on-white text and similar “invisible” text in files. dtSearch also includes options for searching embedded objects in Microsoft Office documents, and normally hidden content in HTML.
While HTML comments, scripts, links, and styles are not by default included in indexing, dtSearch has an option to include these.
- dtSearch Desktop/Network: Click Options > Preferences > Indexing Options, and check the box to ”Index HTML scripts, styles, links and comments.“
- dtSearch Developer API: Set Options.FieldFlags = to a combination of these flags: dtsoFfHtmlShowLinks, dtsoFfHtmlShowImgSrc, dtsoFfHtmlShowComments, dtsoFfHtmlShowScripts, dtsoFfHtmlShowStylesheets, and dtsoFfHtmlShowMetatags.
A similar option searches hidden content (such as Macros or other embedded objects) in Microsoft Office files.
- dtSearch Desktop/Network: Click Options > Preferences > Indexing Options, and check the box to “Index Hidden content in Office documents.”
- dtSearch Developer API: This option is set by default. To disable it, set dtsoFfOfficeSkipHiddenContent in Options. FieldFlags.
Disk Images
To index and search the contents of a disk image, mount the disk image so it is visible as part of the Windows file system. dtSearch can then index the mounted image like other Windows folders. (For programmers, the DataSource API supports direct indexing of disk images.)
Multicolor Hit-Highlighting
To easily distinguish among different search terms in search results, dtSearch now offers the option to highlight each search term or phrase in a search request in a different color. dtSearch products offer an option to enable multicolor hit-highlighting and to change the colors used for highlighting.
- dtSearch Desktop/Network, Click Options > Preferences > Fonts and Color.
Note: this option applies to text converted to HTML for browser display; not PDF display.
dtSearch also offers an option to show the first hits in context in search results as well.
- dtSearch Desktop/Network: Click Options > Preferences > Search Options > Search results and check the box: First hits in context
See also caching for storing complete documents is useful in situations where the documents may not be accessible at search time, or where access to the documents may be slow or unreliable.
Caching
dtSearch products also include a caching option for use with web-based or other remote data, or for faster generation of search reports.
Cache document text in the index. Storing the text of documents makes generation of search reports much faster, including generation of the brief hits-in-context synopsis in search results.
Cache documents in the index. Storing complete documents is useful in situations where the documents may not be accessible at search time, or where access to the documents may be slow or unreliable.
- dtSearch Desktop/Network: Select caching options in Index > Create Index (Advanced)
- dtSearch Developer API: Use caching flags to enable caching when indexing using the API.
Search for List of Words; Hits by Word; Concept Search; Search Report
Search for List of Words. dtSearch provides an option to search for a list of words. Under this option, a special dialog box provides a way to search for a long list of words, and create a list of matching files, in a single step. This option can work with the full range of dtSearch search features (Boolean, fuzzy, natural language, etc.). More information
Hits by word. dtSearch can also provide a hit count by word.
- dtSearch Desktop/Network: Click Search > Search for List of Words... Then select a CSV report under “Type of file to create.” And select “Hit count by word” under “Columns to export.” You can also get hits by word for individual documents by clicking View > Document Information after opening a document in dtSearch.
Concept Search. For expanding a search for a specific set of word or words to a user-defined list of concepts or synonyms, dtSearch also offers a user-defined thesaurus add-on to the comprehensive English-language thesaurus included with dtSearch.
- dtSearch Desktop/Network: Click Options > Preferences > Search Options > User thesaurus to add a list of synonym rings to a specific terms.
Search Report. A search report is good option for quickly going through a large number of retrieved files. This works with all retrieved files or selected retrieved files (see below). A search report lists each hit found in each of the documents retrieved in a search with a specified number of words or paragraphs of context surrounding it.
- dtSearch Desktop/Network: From a search results window, select Search > Search Report
See also caching for faster search report generation.
Selecting and Copying Retrieved Files
Selecting Retrieved Files. dtSearch has an option to select specific retrieved items in search results and have these remain selected as you continue to explore search results.
- dtSearch Desktop/Network: Click Options > Preferences > Search Options > Search Results followed by Checkbox under "Items to include in search results"
Copying Retrieved Files. dtSearch’s Edit › Copy File function lets you copy all or selected documents retrieved from a search to a folder. You can optionally preserve the full path and filename in the copy, and you can preserve creation and last access times as well as the last modified date. Copy File also gives you the option of copying a single item in a container file such as a ZIP or PST archive, rather than copying the whole container. More information
Making Available Retrieved Files on Portable Media
The dtSearch Publish product can quickly publish forensically retrieved (or e-discovery retrieved) documents to portable media. The resulting product provides instant search and display access to the document set. The portable media can run with zero footprint, requiring no installation on the end-user's computer.
Please see Mirroring Searchable Web Content on Portable Media article (PDF) for an overview of how dtSearch Publish works.
Back To Top